Linux进程复制与替换
在Linux系统中,fork()是创建新进程的核心系统调用,它通过“复制父进程”生成子进程,二者形成独立但关联的执行单元。理解fork()的返回特性、父子进程关系及底层优化机制,是掌握多进程编程的基础。
fork()函数的基本用法与返回特性
fork()函数用于创建新进程,调用者为父进程,新生成的进程为子进程,其核心特点是“一次调用,两次返回”,返回值是区分父子进程的关键。
函数定义与返回值
fork()的函数原型为:
1 |
|
返回值类型:pid_t本质是int类型(Linux内核中通过typedef定义),用于表示进程ID。
返回规则(核心特性):
父进程中:返回子进程的PID(正整数),用于父进程识别和管理子进程;
子进程中:返回0(无特殊含义,仅作为子进程的标识);
失败时:返回**-1**(如系统资源不足、进程数达到上限),并设置
errno提示错误原因。
父子进程的执行逻辑
fork()调用后,子进程并非从main函数开始执行,而是从fork()调用的下一行代码继续执行,且初始状态与父进程完全一致:
- 父进程在
fork()前分配的内存(如变量、数组)、打开的文件、寄存器状态,会被子进程复制(实际通过“写时拷贝”优化,非立即全量复制); - 唯一区别是
fork()的返回值:父进程拿到子进程PID,子进程拿到0,以此为依据可编写分支逻辑(如父进程执行A任务,子进程执行B任务)。
示例代码:
1 |
|
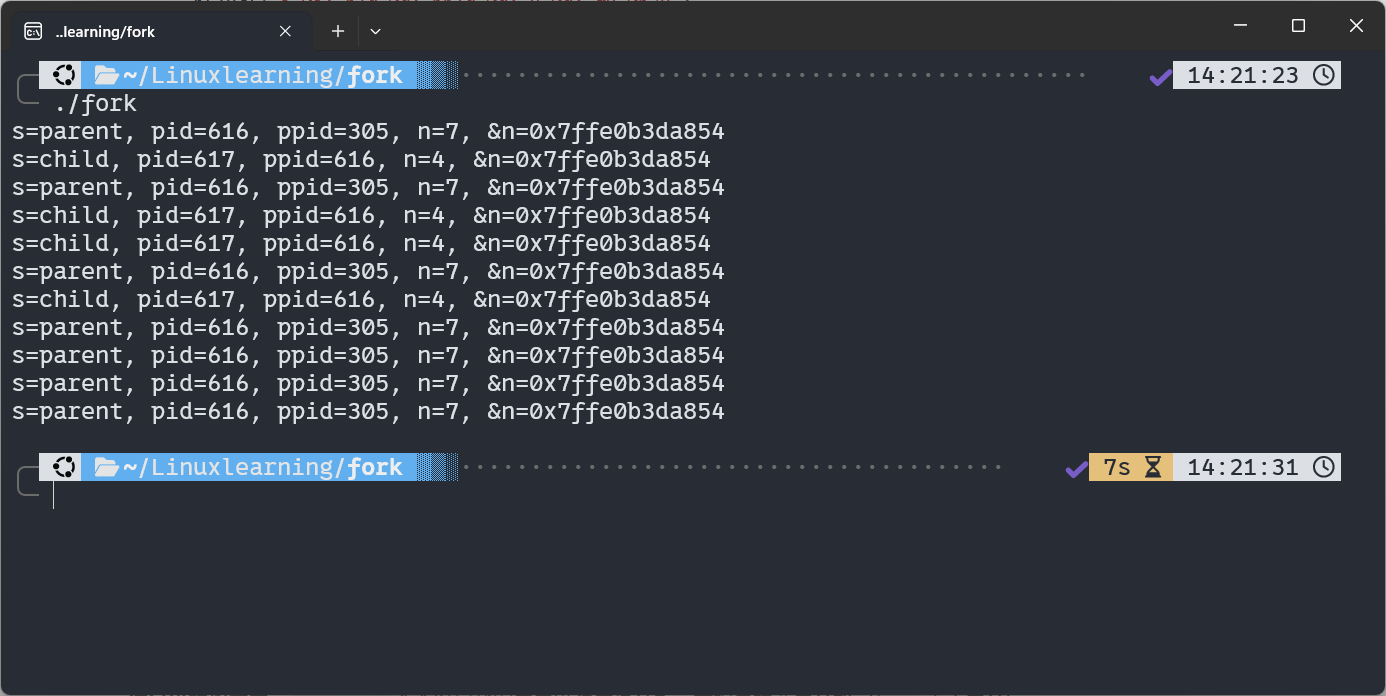
输出特点:父子进程会交替打印(由系统调度决定),且各自的n值不同(子进程n=4,父进程n=7),说明变量已独立。
父子进程的识别与进程树关系
避免“PID大小判断”的误区
早期常通过“父进程PID大于子进程PID”判断父子关系,但PID重用机制会打破这一规律:当早期创建的小PID进程退出(如PID=100),新进程(可能是子进程)会优先重用该PID,导致父进程PID(如2000)大于子进程PID(100)。
正确识别方法
- 通过PPID判断:子进程的“父进程ID(PPID)”一定等于父进程的PID,可通过
ps -ef或ps -l查看。例如:1
ps -ef | grep 子进程PID # 输出中PPID列即为父进程PID
- 通过进程树查看:
pstree -p命令以树状图展示进程层级关系,直观呈现父子关联(与PID大小无关)。
终端、bash与用户进程的关系
当打开终端时,进程层级为:终端进程 → bash进程 → 用户进程(父) → 用户进程(子,由fork创建)
- 终端进程是bash的父进程,bash是用户输入命令(如
./a.out)的父进程; - 可通过
echo $$查看当前bash的PID,通过pstree -p验证层级关系。
父子进程的并发运行特性
fork()创建的子进程与父进程是并发运行的,其本质是操作系统通过“进程调度器”动态分配CPU时间片,实现多任务“同时执行”的效果。
并发的核心本质
- 独立性:子进程拥有独立的地址空间(写时拷贝机制保障)、寄存器状态和执行序列,父进程的阻塞(如
sleep、I/O等待)不会影响子进程。 - 调度随机性:CPU时间片分配由调度器(如Linux的CFS调度器)决定,父子进程的执行顺序不确定。例如多次运行同一程序,子进程可能先打印,也可能父进程先打印。
- 宏观并行,微观交替:单CPU核心上,父子进程通过快速切换实现“同时运行”;多核心系统上,二者可能被分配到不同核心,实现真正的并行。
并发与串行的对比
- 串行:父进程调用
wait()等函数等待子进程结束后再继续执行,本质是“先子后父”或“先父后子”的顺序执行,无CPU时间片切换。 - 并发:父子进程在时间上重叠执行,调度器根据优先级和时间片策略动态切换,资源利用率更高,但需注意共享资源的竞争问题(如共享文件的读写冲突)。
逻辑地址与物理地址
进程运行时使用“逻辑地址”,而硬件访问内存依赖“物理地址”,二者通过内存管理单元(MMU)实现转换,是理解进程内存隔离的关键。
逻辑地址(虚拟地址)
- 定义:程序编译、运行时使用的地址,对应进程的“虚拟地址空间”(如32位进程看到的4GB连续地址),由CPU生成。
- 特点:
- 对程序而言,逻辑地址是连续的(即使物理内存不连续),无需关心实际硬件布局;
- 进程间逻辑地址隔离:A进程的0x1234地址与B进程的0x1234地址,指向不同的物理内存,互不干扰;
- 需转换为物理地址才能访问硬件,转换由MMU完成。
物理地址
- 定义:实际物理内存(RAM)的硬件地址,对应内存芯片中的存储单元,是内存控制器可直接识别的地址。
- 特点:
- 地址范围由物理内存大小决定(如8GB内存的物理地址范围是0~0x1FFFFFFFF);
- 物理地址可能不连续(由内存分配和碎片导致);
- 无需转换,直接用于硬件寻址,但无隔离性(内核模式下可直接操作,用户模式下禁止)。
地址转换机制:MMU与页表
逻辑地址到物理地址的转换依赖MMU(内存管理单元) 和页表(Page Table),核心步骤如下:
- 程序生成逻辑地址(如0x12345678),MMU将其拆分为“页号(Page Number)”和“页内偏移(Offset)”;
- 页号作为索引查询页表,找到对应的“物理页框号(Frame Number)”;
- 物理页框号与页内偏移组合,生成最终的物理地址(如0x87654321),用于访问内存单元。
- 页表作用:记录逻辑页与物理页框的映射关系,同时实现内存保护(如只读、可执行权限)和虚拟内存(未使用的逻辑页可映射到磁盘交换区)。
核心区别对比
| 特性 | 逻辑地址(虚拟地址) | 物理地址 |
|---|---|---|
| 使用者 | 应用程序 | 硬件(内存控制器、MMU) |
| 地址范围 | 由CPU位数决定(32位=4GB) | 由物理内存大小决定(如8GB) |
| 连续性 | 程序中表现为连续 | 可能分散(由内存分配决定) |
| 转换需求 | 需MMU转换为物理地址 | 无需转换,直接访问硬件 |
| 安全性 | 进程间隔离,无相互访问风险 | 无隔离性,直接暴露硬件地址 |
fork()的内存优化机制
Linux在fork()创建子进程时,并非立即全量复制父进程的内存空间,而是采用“写时拷贝(Copy-On-Write)”优化,减少冗余开销。
为什么需要写时拷贝?
传统fork()会完整复制父进程的地址空间(代码段、数据段、堆、栈),但实际场景中:
- 子进程创建后常立即调用
exec系列函数(加载新程序),复制的内存会被直接丢弃,造成无效开销; - 即使不调用
exec,父子进程也可能长时间只读共享数据(如配置文件、常量),全量复制浪费内存和CPU资源。
COW通过“延迟复制”解决这一问题,仅在需要修改时复制内存页,显著提升fork()效率。
工作原理
创建子进程时:共享内存
fork()后,内核不为子进程分配新内存页,而是让父子进程共享父进程的所有内存页,并将这些页标记为“只读”;同时更新二者的页表,让逻辑地址指向同一块物理内存。修改内存时:触发复制
若父进程或子进程尝试修改共享内存页,CPU会检测到“对只读页的写入操作”,触发“页错误(Page Fault)”中断;内核捕获中断后,为修改方复制一份新的内存页,更新其页表映射(指向新物理页),未修改的页仍保持共享。最终效果
仅复制被修改的内存页,未修改的页继续共享,实现“按需复制”,减少初始开销和内存占用。
示例验证COW效果
1 |
|

分析:子进程修改变量时触发COW,复制新内存页,因此父进程的变量值保持初始状态,二者内存完全独立。
进程控制块(PCB)
进程控制块(PCB)是操作系统内核中描述和管理进程的核心数据结构,每个进程对应一个PCB,是进程存在的唯一标识(操作系统通过PCB识别进程)。
PCB的核心作用
- 存储进程的所有状态信息(如PID、状态、资源占用),作为操作系统调度、管理进程的依据;
- 实现进程的“断点续存”:进程切换时,内核将CPU上下文(寄存器、程序计数器)保存到PCB,恢复时从PCB读取,确保进程从断点继续执行。
PCB包含的核心信息(以Linux的task_struct为例)
进程标识信息
- PID(进程ID):系统唯一的进程编号,用于标识进程;
- PPID(父进程ID):记录父进程PID,维护进程树关系;
- UID/GID(用户/组ID):标识进程所属用户和组,用于权限控制(如判断是否有权访问文件)。
进程状态信息
- 进程状态:如运行(Running)、就绪(Ready)、阻塞(Blocked)、终止(Terminated);
- 等待原因:若阻塞,记录阻塞原因(如等待I/O完成、等待信号量)。
调度信息
- 优先级:进程被调度的优先级别(数值越小优先级越高,或反之,依系统而定);
- 调度策略:如CFS(完全公平调度)、实时调度,决定进程如何获取CPU时间片;
- 时间片信息:已使用的CPU时间、剩余时间片,用于调度器分配资源。
资源信息
- 内存地址空间:记录进程逻辑地址范围(代码段、数据段、堆、栈的起始和结束地址);
- 打开文件列表:进程打开的文件描述符(如文件、管道、套接字);
- I/O设备:进程占用的I/O设备(如键盘、显示器),及设备状态。
CPU上下文信息
- 寄存器状态:程序计数器(PC,记录下一条指令地址)、栈指针(SP)、通用寄存器(如eax、ebx);
- CPU状态字:记录CPU的状态(如中断屏蔽标志、运算结果标志),用于进程切换时恢复执行状态。
PCB的生命周期
- 进程创建(
fork()):内核为新进程分配task_struct,初始化标识、状态、资源等信息; - 进程运行:内核通过PCB跟踪进程状态,调度时读写上下文信息;
- 进程终止(
exit()):内核释放PCB及关联资源(如内存、文件描述符),PCB被销毁。
fork()方法
fork()循环与输出次数分析
fork()在循环中调用时,子进程会复制父进程的当前状态(包括循环变量、缓冲区内容等),导致输出次数随进程数量呈指数增长。以下结合三个代码示例,拆解输出逻辑:
代码1:printf("A\n") 输出6个”A”
1 | int main() { |
执行过程拆解(核心:\n触发缓冲区刷新,子进程无继承缓冲区内容)
- 循环变量
i的初始值为0,循环条件i < 2(共执行2次循环:i=0和i=1)。
第一次循环(
i=0):- 父进程执行
fork(),创建子进程1(记为P1)。 printf("A\n")中\n会立即刷新缓冲区,父进程输出1个”A”;子进程1复制父进程状态(i=0),同样输出1个”A”。- 循环结束后,父进程和子进程1的
i均自增为1。
- 父进程执行
第二次循环(
i=1):- 父进程:执行
fork(),创建子进程2(P2),printf输出1个”A”; - 子进程1:执行
fork(),创建子进程3(P3),printf输出1个”A”; - 子进程2(P2)复制父进程状态(
i=1),printf输出1个”A”; - 子进程3(P3)复制子进程1状态(
i=1),printf输出1个”A”。
- 父进程:执行
总输出:1(父)+1(P1)+1(父)+1(P2)+1(P1)+1(P3)= 6个”A”。

代码2:printf("A") 输出8个”A”
1 | int main() { |
执行过程拆解(核心:无\n时,缓冲区内容被子进程继承)
printf("A")的内容会暂存于缓冲区(未刷新),fork()会复制父进程的缓冲区,导致子进程继承未输出的”A”。
第一次循环(
i=0):- 父进程
fork()创建子进程1(P1),此时父进程缓冲区有1个”A”(未输出)。 - 循环结束,父进程和P1的
i自增为1(缓冲区仍有1个”A”)。
- 父进程
第二次循环(
i=1):- 父进程:
fork()创建子进程2(P2),缓冲区新增1个”A”(共2个”A”); - 子进程1:
fork()创建子进程3(P3),缓冲区新增1个”A”(共2个”A”); - 循环结束,所有进程
i=2退出循环,exit(0)触发缓冲区刷新。
- 父进程:
各进程刷新的缓冲区内容:
父进程:2个”A” → 输出2个;
P1:2个”A” → 输出2个;
P2:继承父进程2个”A” → 输出2个;
P3:继承P1的2个”A” → 输出2个。
总输出:2+2+2+2= 8个”A”。

代码3:fork()||fork() 输出3个”A”
1 | int main() { |
执行过程拆解(核心:逻辑或||的短路特性)
||运算中,若左表达式为真(非0),则右表达式不执行;若左为假(0),则执行右表达式。
父进程:
- 第一个
fork()返回子进程PID(非0,左表达式为真),||短路,右fork()不执行。 - 执行
printf("A\n")→ 输出1个”A”。
- 第一个
第一个
fork()创建的子进程(P1):- 第一个
fork()在子进程中返回0(左表达式为假),执行右fork(),创建子进程2(P2)。 - P1执行
printf("A\n")→ 输出1个”A”。
- 第一个
第二个
fork()创建的子进程(P2):- 右
fork()在子进程中返回0,直接执行printf("A\n")→ 输出1个”A”。
- 右
总输出:1(父)+1(P1)+1(P2)= 3个”A”。

父进程与子进程的生命周期问题
当父进程与子进程的结束顺序不同时,会产生“孤儿进程”或“僵尸进程”,系统有特定机制处理这两种情况。
父进程先结束:子进程成为“孤儿进程”
现象:父进程先退出,子进程失去父进程,被系统的“收养进程”(传统为
init进程,PID=1;现代系统多为systemd)接管。特点:
- 子进程可继续正常运行,不受父进程退出影响;
- 子进程的PPID(父进程ID)会变为收养进程的PID(通常为1);
- 系统自动处理,无需手动干预。
1
2
3
4
5
6
7
8
9
10
11
12
13# 后台运行sleep进程(父进程为当前bash,PID假设为567)
$ sleep 60 &
[1] 1234
# 查看子进程PPID为567
$ ps -o pid,ppid -p 1234
PID PPID
1234 567
# 关闭bash(父进程567退出),重新查看:PPID变为1
$ ps -o pid,ppid -p 1234
PID PPID
1234 1
子进程先结束:父进程未回收则成为“僵尸进程”
现象:子进程退出后,内核会保留其进程表项(记录退出状态等信息),等待父进程通过
wait()或waitpid()回收。若父进程未处理,子进程会成为“僵尸进程”(状态标记为Z+)。特点:
- 僵尸进程已释放大部分资源(如内存、文件描述符),但仍占用PID;
- 大量僵尸进程可能耗尽系统PID资源,导致无法创建新进程;
- 父进程退出后,僵尸进程会被收养进程回收。
示例代码(产生僵尸进程):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int main() {
pid_t pid = fork();
if (pid == 0) {
// 子进程:立即退出
printf("子进程 %d 退出\n", getpid());
return 0;
} else {
// 父进程:不调用wait(),无限循环
while(1) { sleep(1); }
}
}运行后,通过
ps -ef | grep defunct可看到子进程状态为Z+(僵尸进程)。
核心对比表
| 场景 | 进程状态 | 系统处理机制 | 解决方式 |
|---|---|---|---|
| 父进程先结束 | 子进程成为孤儿进程 | 被init/systemd(PID=1)收养 |
无需手动处理 |
| 子进程先结束(未回收) | 子进程成为僵尸进程 | 保留进程表项,等待父进程wait()回收 |
父进程调用wait()/waitpid() |
通过理解fork()的复制特性、缓冲区继承规律,以及进程生命周期的处理机制,可准确预测多进程程序的输出结果,并避免僵尸进程等资源泄漏问题。
僵死进程及其处理方法
僵死进程(Zombie Process)是Linux多进程编程中常见的资源残留问题,核心源于子进程终止后父进程未及时回收其资源。理解其产生机制与处理方法,是避免系统PID耗尽、资源泄漏的关键。
僵死进程的核心概念与产生原因
当子进程先于父进程终止,且父进程未通过wait()/waitpid()系统调用回收子进程的进程控制块(PCB) 时,子进程的PID、退出状态等信息会残留于系统中,此时子进程即处于僵死状态(标记为Z),称为僵死进程。
子进程终止时,内核不会立即释放其所有资源——为了让父进程获取子进程的退出状态(如退出码、终止原因),内核会保留子进程的PCB(含PID、退出状态、CPU使用时间),等待父进程主动回收。若父进程满足以下任一条件,子进程会成为僵死进程:
- 未调用回收函数:父进程代码逻辑遗漏
wait()/waitpid(),未主动获取子进程退出状态; - 父进程长期运行:父进程陷入无限循环(如
while(1) { sleep(1); })或持续处理任务,未触发回收逻辑; - 父进程忽略信号:子进程终止时会向父进程发送
SIGCHLD信号,若父进程未注册该信号的处理函数且未阻塞,信号会被忽略,导致资源无法回收。
僵死进程的特点与危害
核心特点
- 状态标记为
Z:通过ps命令查看时,进程状态列显示为Z,进程名后标注<defunct>(意为“已失效”),示例:1
2$ ps -ef | grep Z
user 1234 567 0 10:00 pts/0 00:00:00 [a.out] <defunct> - 资源部分释放:僵死进程已释放内存、打开的文件、网络连接等大部分资源,仅残留PCB(约几十字节)和PID;
- 无法被杀死:向僵死进程发送
SIGKILL(强制终止信号)无效——因进程实体已终止,仅PCB残留,信号无对象可作用。
潜在危害
- PID资源耗尽:系统PID范围有限(通常为32768或更大,可通过
/proc/sys/kernel/pid_max查看),大量僵死进程会占用PID,导致新进程无法创建; - 系统管理混乱:长期积累的僵死进程会增加系统进程管理的复杂度,且残留的PCB会占用少量内核内存,虽单个影响微小,但大规模残留仍可能影响系统稳定性。
僵死进程的处理方法
处理僵死进程的核心是“让操作系统回收子进程的PCB”,主要有三种实现方式,其中“父进程主动回收”是最推荐的常规方案。
父进程主动回收:wait()与waitpid()(推荐)
父进程通过wait()或waitpid()系统调用,主动获取子进程退出状态并触发资源回收,从根源避免僵死进程。
(1)wait(NULL):简化回收(无需退出状态)
当父进程不关心子进程的退出细节(如退出码、终止原因)时,使用wait(NULL),仅需回收资源。
- 函数原型:
pid_t wait(int *status);
参数传NULL表示“不保存子进程退出状态”,仅要求内核回收PCB。 - 核心作用:阻塞父进程,直到任意一个子进程终止后,回收该子进程资源,父进程再继续执行;若子进程已终止,会立即回收资源(非阻塞)。
- 代码示例(解决僵死进程):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
int main() {
pid_t pid = fork();
if (pid == -1) { exit(1); } // fork失败
if (pid == 0) {
// 子进程:打印3次后退出
for (int i = 0; i < 3; i++) {
printf("子进程:第%d次打印\n", i+1);
sleep(1);
}
exit(3); // 子进程退出码为3
} else {
// 父进程:调用wait(NULL)回收子进程,不关心退出状态
wait(NULL); // 核心:回收资源,避免僵死进程
printf("父进程:子进程已回收,开始打印\n");
// 父进程打印7次
for (int i = 0; i < 7; i++) {
printf("父进程:第%d次打印\n", i+1);
sleep(1);
}
}
return 0;
} - 执行效果:子进程先打印3次,父进程等待子进程回收后再打印7次,无僵死进程残留。
(2)wait(&val):回收并获取退出状态
若父进程需要知道子进程的退出方式(正常退出/被信号杀死)或退出码,使用wait(&val),通过val存储退出状态,再用专用宏解析。
- 关键宏解析:
WIFEXITED(val):判断子进程是否正常退出(通过exit()或return,非被信号杀死),返回非0表示正常退出;WEXITSTATUS(val):仅当WIFEXITED(val)为真时,提取子进程的退出码(即exit(n)中的n)。
- 代码示例(获取退出码):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
int main() {
pid_t pid = fork();
if (pid == -1) { exit(1); }
if (pid == 0) {
// 子进程:打印3次后退出,退出码为3
for (int i = 0; i < 3; i++) {
printf("子进程:第%d次打印\n", i+1);
sleep(1);
}
exit(3);
} else {
int val;
wait(&val); // 回收子进程,退出状态存入val
// 解析退出状态
if (WIFEXITED(val)) {
// 正常退出,提取退出码
printf("子进程正常退出,退出码:%d\n", WEXITSTATUS(val));
}
// 父进程后续逻辑
printf("父进程开始打印\n");
for (int i = 0; i < 7; i++) {
printf("父进程:第%d次打印\n", i+1);
sleep(1);
}
}
return 0;
} - 执行效果:子进程退出后,父进程打印“子进程正常退出,退出码:3”,再执行后续打印,既回收资源,又获取退出细节。
(3)wait()与wait(NULL)的区别
| 对比维度 | wait(&val) |
wait(NULL) |
|---|---|---|
| 核心功能 | 回收资源 + 保存子进程退出状态 | 仅回收资源,不保存退出状态 |
| 适用场景 | 父进程需要知道子进程退出码/终止原因 | 父进程不关心子进程退出细节 |
| 代码复杂度 | 需用宏解析状态,略复杂 | 无需解析,代码简洁 |
| 防僵死效果 | 有效 | 有效(核心功能一致) |
父进程退出:由init/systemd收养回收
若父进程先于子进程终止,子进程会成为“孤儿进程”,被系统的“收养进程”(传统Linux为init进程,PID=1;现代系统多为systemd)接管。收养进程会定期调用wait()回收所有子进程,残留的僵死进程也会随之被清理。
- 示例:若父进程因代码错误提前退出,子进程的PPID(父进程ID)会变为1,最终被
init回收,不会残留为僵死进程。 - 局限性:需依赖父进程退出,无法主动控制,仅适用于父进程短期运行的场景(如临时脚本)。
信号处理:SIGCHLD信号自动回收
子进程终止时,内核会向父进程发送SIGCHLD信号。父进程可注册该信号的处理函数,在信号触发时自动调用waitpid()回收子进程,避免父进程阻塞(适用于父进程需并发处理多个任务的场景)。
- 代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// SIGCHLD信号处理函数:回收所有已退出的子进程
void handle_sigchld(int sig) {
// waitpid(-1, NULL, WNOHANG):非阻塞回收所有子进程
while (waitpid(-1, NULL, WNOHANG) > 0);
}
int main() {
// 注册SIGCHLD信号处理函数
signal(SIGCHLD, handle_sigchld);
// 创建子进程
pid_t pid = fork();
if (pid == -1) { exit(1); }
if (pid == 0) {
// 子进程:5秒后退出
sleep(5);
exit(0);
} else {
// 父进程:无需阻塞,正常执行其他任务
while (1) {
printf("父进程正在运行...\n");
sleep(1);
}
}
return 0;
} - 关键参数:
waitpid(-1, NULL, WNOHANG)-1:回收所有子进程;NULL:不保存退出状态;WNOHANG:非阻塞模式,若无子进程可回收,立即返回0,不阻塞父进程。
典型场景对比
未处理僵死进程的代码
1 |
|
- 运行结果:子进程退出后,通过
ps -ef | grep Z可看到其状态为Z+ <defunct>,成为僵死进程。
已处理僵死进程的代码
在上述代码的父进程分支中添加wait(NULL):
1 | else { |
- 运行结果:子进程退出后,
ps命令无僵死进程残留,资源被正常回收。
僵死进程的本质是“子进程PCB未被回收”,处理的核心是通过wait()/waitpid()主动回收,或依赖系统收养机制。日常开发中:
- 若无需子进程退出状态,优先使用
wait(NULL),代码简洁且能有效防僵尸; - 若需获取退出码(如判断子进程任务是否成功),使用
wait(&val)配合宏解析; - 若父进程需并发运行(如服务端程序),通过
SIGCHLD信号+waitpid(WNOHANG)实现非阻塞回收。
合理使用这些方法,可彻底避免僵死进程导致的PID耗尽、资源泄漏问题。
从进程的视角看堆区内存申请与释放的有关问题
进程地址空间中的堆
在进程的虚拟地址空间中,堆是动态内存区域,用于存储进程运行中“按需申请、手动释放”的数据(如动态数组、结构体实例等),其定位和特点需结合进程地址空间布局理解:
堆在进程地址空间中的位置
进程虚拟地址空间从低到高大致分为:代码段(.text)→ 数据段(.data/.bss)→ 堆(Heap) → 共享库映射区 → 栈(Stack)。
堆的增长方向是从低地址向高地址动态扩展,与栈(从高地址向低地址增长)形成“中间扩展”的布局,两者之间的“内存空洞”会随堆和栈的动态使用而变化——堆扩展时向空洞占用空间,栈扩展时也向空洞占用空间,直到两者接近(内存耗尽)。
堆与其他内存区域的核心区别
堆是进程中唯一需要手动管理的内存区域,与栈、数据段的差异显著,具体对比如下:
| 内存区域 | 管理方式 | 大小限制 | 生命周期 | 典型用途 |
|---|---|---|---|---|
| 堆 | 手动申请(malloc/calloc/realloc)、手动释放(free) | 受物理内存大小+交换区大小限制,无固定上限 | 由进程控制(未释放则持续到进程退出) | 动态数组、结构体实例、大体积数据(如文件缓存) |
| 栈 | 编译器自动分配(函数内定义局部变量时)、自动释放(函数退出时) | 固定大小(Linux默认约8MB,可通过ulimit -s配置) |
与函数调用周期绑定,函数退出后内存自动回收 | 局部变量、函数参数、函数返回值 |
| 数据段(.data/.bss) | 编译器编译时分配,进程启动时初始化 | 编译期确定大小,运行中不可动态调整 | 进程整个生命周期(从启动到退出) | 全局变量、静态变量(static修饰) |
堆内存的申请机制:从进程调用到内核交互
进程无法直接操作物理内存,堆内存的申请需通过“用户态内存分配器”(如Linux下glibc库的ptmalloc、Google的tcmalloc)与“内核”协作完成。这种分层设计的核心目的是“减少内核调用开销”——内核调用(如brk/mmap)耗时较高,分配器通过维护“内存池”复用内存,避免频繁向内核请求。
内存分配器的核心角色
用户态分配器是进程与内核之间的“中间层”,主要负责:
- 维护“空闲块链表”:将未使用的堆内存块按大小分类(如小块、中块、大块),存储在不同链表中,方便快速查找;
- 内存块管理:为每个堆内存块添加“头部元数据”(如块大小、是否已分配、前后块指针),用于标记状态和合并空闲块;
- 内核交互代理:仅当内存池中的空闲块无法满足申请需求时,才向内核申请新内存,再加入内存池供进程使用。
堆内存申请的核心流程(以malloc为例)
第一步:检查分配器的“空闲块链表”
当进程调用malloc(size)申请内存时,分配器首先在“空闲块链表”中查找合适的空闲块,查找策略通常有两种:
- 首次适配(First Fit):遍历空闲链表,找到第一个大小≥
size的空闲块,效率高但可能产生较多碎片; - 最佳适配(Best Fit):遍历所有空闲块,找到大小最接近且≥
size的空闲块,碎片少但遍历成本高。
找到合适的空闲块后,分配器会:
- 若块大小与
size完全匹配:直接将块从空闲链表中移除,标记为“已分配”; - 若块大小大于
size:将块分割为两部分——一部分为size大小的“已分配块”(返回给进程),另一部分为剩余大小的“空闲块”(留在空闲链表中)。
第二步:无合适空闲块时,向内核申请内存
若空闲链表中无满足size的块,分配器会根据申请的内存大小,通过两种不同的内核调用方式请求内存:
| 申请内存大小 | 内核调用方式 | 原理 | 适用场景 |
|---|---|---|---|
小内存(如<128KB,ptmalloc默认阈值) |
brk()系统调用 |
调整进程的“堆顶指针”(program break,简称brk)——brk是堆区的“边界指针”,初始指向堆底,调用brk(new_brk)可将堆顶向高地址扩展,新增的内存区域直接加入分配器的空闲池 |
频繁申请的小内存(如结构体、短数组),释放后可与相邻空闲块合并,复用率高,减少内核交互 |
| 大内存(如≥128KB) | mmap()系统调用 |
向内核申请一块“匿名内存页”(不关联任何磁盘文件的内存),内核会将该内存页映射到进程虚拟地址空间的“共享库映射区”(独立于堆区),分配器直接将这块内存返回给进程 | 单次申请的大内存(如1MB的数组、大文件缓存),避免小内存池中的碎片问题;释放时可直接归还给内核,不占用内存池 |
第三步:返回申请结果与合法性检查
- 申请成功:分配器返回指向“已分配块”的逻辑地址(虚拟地址),进程可通过该地址读写内存;
- 申请失败:返回
NULL,通常因系统内存不足(brk/mmap调用返回错误),因此进程必须养成“malloc后检查NULL”的习惯,示例:1
2
3
4
5
6// 申请10个int类型的内存(共40字节)
int *p = (int*)malloc(10 * sizeof(int));
if (p == NULL) { // 检查申请结果,避免后续空指针访问
perror("malloc failed"); // 打印错误原因(如“Out of memory”)
exit(1); // 异常退出
}
其他申请函数的差异(calloc/realloc)
除malloc外,C标准库还提供calloc和realloc,本质仍是基于分配器和内核调用实现,仅功能细节不同:
calloc(n, size):申请n*size字节的内存,并将所有字节初始化为0(malloc不初始化,内存中是随机值);realloc(p, new_size):调整已分配块p的大小——若new_size小于原大小,直接分割块;若new_size大于原大小,优先尝试在原块后扩展(若相邻区域空闲),无法扩展则申请新块、拷贝数据、释放原块。
堆内存的释放机制:从标记空闲到内核回收
进程调用free(p)释放堆内存时,并非直接将内存归还给内核——核心逻辑是“标记空闲+复用”,仅在特定场景下(如大内存释放)才归还给内核,以减少内核交互开销。
释放的核心流程(以free为例)
第一步:验证释放的内存块合法性
分配器首先检查p指向的地址是否合法,避免非法释放导致崩溃,验证内容包括:
p是否指向分配器管理的堆内存块(通过块头部的元数据标记判断);- 该内存块是否已被释放(避免“双重释放”);
p是否为块的起始地址(避免释放块中间地址)。
若验证失败,会触发错误(如double free or corruption),进程直接崩溃。
第二步:标记为空闲块,加入空闲链表
根据内存块的申请方式(brk或mmap),释放逻辑不同:
brk申请的小内存块:释放后不直接归还给内核,仅将块的“已分配”标记改为“空闲”,并加入对应的空闲块链表;同时更新块的元数据(如前后块指针),便于后续合并;mmap申请的大内存块:释放时会调用munmap(p, size)系统调用,将该内存页直接归还给内核——内核会解除该内存页与进程虚拟地址空间的映射,后续进程访问p会触发“段错误(Segmentation Fault)”。
第三步:空闲块合并(解决外部碎片)
释放的空闲块可能与前后相邻的空闲块“接壤”(如前一个块和后一个块均为空闲),分配器会将这些块合并为一个大的空闲块,避免“外部碎片”(即空闲块总大小足够,但分散成小块无法满足大内存申请)。
合并逻辑依赖块头部的“前后块指针”:分配器通过元数据找到当前块的前块和后块,若前块/后块为空闲状态,则将三者合并为一个新的空闲块,更新空闲链表中的指针,确保后续申请时能使用合并后的大块。
关键概念:内存碎片
堆内存管理的核心挑战是“内存碎片”,从进程视角看,碎片会导致“明明系统有足够内存,却无法申请到连续的内存块”,主要分为两类:
| 碎片类型 | 产生原因 | 影响与解决思路 |
|---|---|---|
| 内部碎片 | 分配的块大小大于申请的大小(如进程申请90KB,分配器因块大小对齐(如按8字节对齐),分配100KB,多余的10KB无法使用) | 分配器采用“按大小分类的空闲链表”(如将小块按8/16/32字节划分),减少分割时的剩余空间;或使用“内存对齐优化”,平衡对齐需求与碎片 |
| 外部碎片 | 空闲块分散在已分配块之间,总大小足够但无连续块满足申请(如进程申请200KB,空闲块为150KB+80KB,两者不相邻) | 分配器在释放时强制合并相邻空闲块;采用“伙伴系统”(将内存块按2的幂次划分,如8KB、16KB、32KB,合并时只需检查“伙伴块”是否空闲) |
进程视角下的堆内存管理风险与问题
从进程运行稳定性和资源利用角度,堆内存的申请与释放若操作不当,会导致严重问题,甚至引发进程崩溃或系统资源耗尽。
内存泄漏:堆内存“只申请不释放”
进程申请堆内存后,未调用free释放,且持有该内存地址的指针丢失(如指针被覆盖、函数退出时未将指针传递给外部),导致分配器无法识别该块为“空闲”,内存持续被进程占用,直到进程退出。
常见场景:
- 函数内申请内存,退出前未释放且未返回指针:
1
2
3
4void func() {
char *buf = (char*)malloc(1024); // 申请1KB内存
// 未调用free(buf),函数退出后buf指针销毁,内存泄漏
} - 指针被覆盖,原内存地址丢失:
1
2int *p = (int*)malloc(4);
p = (int*)malloc(8); // 原4字节内存的地址被覆盖,无法释放,导致泄漏
对进程的影响
- 短期进程(如脚本、临时工具):影响较小——进程运行时间短,退出后内核会自动回收所有堆内存,泄漏的内存不会长期占用;
- 长期进程(如服务端程序、后台守护进程):影响致命——泄漏的内存会持续累积,堆内存占用越来越大,最终导致:
- 进程性能下降:内存不足时,系统会将部分内存交换到磁盘(Swap),磁盘IO速度远低于内存,导致进程响应变慢;
- 进程被杀死:当系统内存耗尽时,内核的
OOM Killer(Out Of Memory Killer)会根据进程优先级,杀死内存占用最高的进程(可能是当前泄漏进程)。
检测与规避
- 检测工具:Linux下使用
valgrind --leak-check=full ./a.out,可定位泄漏的内存地址、申请时的代码行数和泄漏大小; - 规避方法:养成“申请即规划释放”的习惯,如使用“资源申请后立即检查+函数退出前释放”,或借助智能指针(如C++的
unique_ptr)自动管理。
野指针:释放后继续访问堆内存
进程调用free(p)释放内存后,未将p置为NULL,此时p仍指向“已释放的内存块”——该块可能被分配器重新分配给其他变量,或标记为空闲块。后续通过p读写内存时,会访问“无效内存”,即野指针访问。
对进程的影响
- 访问重新分配的块:覆盖其他变量的数据,导致逻辑错误(如修改了无关变量的值,难以排查);
- 访问未分配的内存:触发“段错误(Segmentation Fault)”,进程直接崩溃。
1 | int *p = (int*)malloc(4); |
规避方法
释放内存后,务必将指针置为NULL,后续访问前检查指针合法性:
1 | int *p = (int*)malloc(4); |
双重释放(double free):重复释放同一块内存
进程对同一块堆内存调用多次free(如free(p); free(p);),会破坏分配器维护的“空闲块链表”结构——链表指针会因重复操作错乱,导致分配器无法正常管理内存。
对进程的影响
直接导致分配器崩溃,进程触发“内存错误”退出,错误信息通常为“double free or corruption (fasttop)”,示例:
1 | int *p = (int*)malloc(4); |
- 释放后将指针置为
NULL:free(NULL)是安全操作(分配器会忽略),即使误调用也不会崩溃; - 维护“内存释放标记”:对复杂场景,可通过布尔变量标记内存是否已释放,释放前检查标记。
堆越界:访问超出申请大小的内存
进程通过malloc申请size字节的内存后,访问了p[size]及以外的地址(如申请10个int类型内存,却访问p[10]),超出了内存块的边界。
对进程的影响
- 覆盖块头部元数据:堆内存块的头部存储“块大小、是否已分配”等元数据,越界访问可能修改这些信息,导致后续
malloc/free时分配器读取错误的元数据,触发崩溃; - 覆盖相邻内存块:若越界地址属于相邻的已分配块,会修改该块的数据,导致逻辑错误;若属于未分配的内存空洞,可能暂时无明显问题,但后续申请时会触发异常。
1 | // 申请3个int(12字节),索引范围0~2 |
- 检测工具:使用
valgrind --tool=memcheck ./a.out,可检测出堆越界的具体代码行数; - 规避方法:明确内存块的大小,使用循环时严格控制索引范围;对动态数组,可额外存储数组长度,访问前检查索引是否合法。
堆内存与进程生命周期的关联
堆内存的生命周期完全与进程绑定,核心规则如下:
- 进程运行中:堆内存的生命周期由进程手动控制——未调用
free释放的内存,会一直被进程占用,即使指针丢失(内存泄漏),也不会被分配器复用; - 进程退出时:无论进程是正常退出(
exit()/return 0)还是异常崩溃(如段错误),内核都会自动回收进程的所有虚拟地址空间资源,包括:- 未释放的堆内存;
- 栈内存;
- 映射的共享库内存;
- 打开的文件描述符(内核关闭)。
这意味着:
- 短期进程(如一次性脚本)即使存在内存泄漏,也不会导致系统资源长期占用——进程退出后内核会清理所有资源;
- 长期进程(如服务端程序)必须严格避免内存泄漏——进程持续运行时,泄漏的内存会不断累积,直到耗尽系统资源。
操作文件的系统调用
文件描述符(FD)
文件描述符(File Descriptor,简称FD)是内核为每个打开的文件(包括普通文件、目录、设备、管道等)分配的非负整数标识,是用户程序与内核交互文件的“桥梁”。
- 核心特性:
- 进程启动时默认打开3个文件描述符:0(标准输入STDIN,对应键盘)、1(标准输出STDOUT,对应屏幕)、2(标准错误STDERR,对应屏幕);
- 后续通过
open()等调用打开的文件,FD按“最小未使用整数”顺序分配(如3、4、5…); - FD本质是“进程文件描述符表”的索引,每个索引对应内核中的“文件表项”(存储文件偏移量、权限、状态等),进程通过FD间接操作内核中的文件对象。
常用文件操作系统调用
文件操作系统调用是内核提供的底层接口,需包含对应的头文件(如<fcntl.h>、<unistd.h>),以下为核心调用的原型、参数解析及示例。
文件打开与创建:open() / creat()
用于打开已存在文件或创建新文件,返回文件描述符(失败返回-1)。
open() 原型(两种形式)
1 |
|
关键参数解析
pathname:文件路径(绝对路径如/home/user/test.txt,相对路径如test.txt);flags:打开模式标志(必选,可组合使用,用|连接):- 基础模式(三选一):
O_RDONLY(只读)、O_WRONLY(只写)、O_RDWR(读写); - 扩展模式:
O_CREAT:文件不存在则创建(需配合mode参数);O_EXCL:与O_CREAT联用,若文件已存在则报错(避免覆盖);O_TRUNC:打开文件时清空原有内容(仅对普通文件有效);O_APPEND:写操作时自动将文件偏移量移到末尾(保证追加写入);
- 基础模式(三选一):
mode:创建文件时的权限(仅flags含O_CREAT时有效),用八进制表示:- 如
0644:所有者可读可写(6)、同组用户可读(4)、其他用户可读(4); - 权限会受进程的
umask影响(最终权限 = mode & ~umask,默认umask为0022)。
- 如
1 |
|
creat() 说明
creat(pathname, mode)是历史调用,功能等价于open(pathname, O_WRONLY | O_CREAT | O_TRUNC, mode),现已被open()替代,不推荐使用。
文件关闭:close()
关闭已打开的文件描述符,释放内核中对应的文件表项资源(若不关闭,进程退出后内核会自动关闭,但可能导致资源泄漏)。
1 |
|
- 参数:
fd为待关闭的文件描述符; - 返回值:成功返回0,失败返回-1(如
fd无效或已关闭)。
1 | int fd = open("test.txt", O_RDONLY); |
文件读写:read() / write()
read()从FD读取数据到缓冲区,write()将缓冲区数据写入FD,是文件I/O的核心调用。
read() 原型
1 |
|
- 参数:
fd:文件描述符;buf:接收数据的用户态缓冲区(需提前分配空间);count:期望读取的最大字节数;
- 返回值:
- 成功:返回实际读取的字节数(可能小于
count,如已到文件末尾或I/O中断); - 0:表示已读到文件末尾(EOF);
- -1:读取失败(需结合
errno判断原因,如EINTR为被信号中断,可重试)。
- 成功:返回实际读取的字节数(可能小于
write() 原型
1 |
|
- 参数:
fd:文件描述符;buf:存储待写入数据的缓冲区;count:期望写入的字节数;
- 返回值:
- 成功:返回实际写入的字节数(可能小于
count,如磁盘满、超出文件大小限制); - -1:写入失败(如
fd无写权限)。
- 成功:返回实际写入的字节数(可能小于
读写示例(结合lseek)
1 |
|
文件定位:lseek()
调整文件的“当前读写位置”(文件偏移量),支持随机读写(默认是顺序读写),是实现“跳读跳写”的关键。
1 |
|
- 参数:
fd:文件描述符;offset:偏移量(正数向后移,负数向前移);whence:偏移基准(三选一):SEEK_SET:以文件开头为基准(offset需≥0);SEEK_CUR:以当前偏移量为基准;SEEK_END:以文件末尾为基准(offset为正时指向文件外,负时指向文件内);
- 返回值:成功返回新的偏移量(相对于文件开头的字节数),失败返回-1。
1 | int fd = open("test.txt", O_RDWR); |
- 某些特殊文件(如管道、终端、网络套接字)不支持
lseek(),调用会返回-1; - 若文件以
O_APPEND模式打开,每次write()前内核会自动将偏移量移到末尾,忽略lseek()的手动设置。
文件元信息与权限:stat() / fstat() / chmod() / chown()
用于获取或修改文件的元数据(大小、权限、创建时间等),是文件管理的常用工具。
stat() / fstat():获取元信息
stat(pathname, &buf):通过文件路径获取元信息;fstat(fd, &buf):通过已打开的FD获取元信息(更高效,避免路径解析);- 依赖
<sys/stat.h>,核心结构体struct stat包含:st_size:文件大小(字节数);st_mode:文件类型与权限(用S_ISREG(st_mode)判断是否为普通文件,st_mode & 0777提取权限位);st_uid/st_gid:文件所有者的UID/GID;st_mtime:文件最后修改时间。
示例:获取文件大小与权限
1 |
|
chmod() / fchmod():修改权限
- 原型:
1
2
3
int chmod(const char *pathname, mode_t mode); // 路径
int fchmod(int fd, mode_t mode); // FD - 示例:将文件权限改为
0755(所有者读写执行,其他读执行):1
2
3
4
5chmod("test.txt", 0755); // 通过路径
// 或
int fd = open("test.txt", O_RDWR);
fchmod(fd, 0755); // 通过FD
close(fd);
chown() / fchown():修改所有者
需root权限,用于变更文件的UID/GID,原型类似chmod,示例:
1 |
|
文件删除与重命名:unlink() / rename()
unlink():删除文件
- 原型:
#include <unistd.h> int unlink(const char *pathname); - 核心逻辑:删除“文件名与inode的关联”(硬链接计数减1),若文件仍被进程打开,实际删除会延迟到最后一个进程关闭FD后;
- 示例:
unlink("old.txt"); // 删除old.txt
rename():重命名/移动文件
- 原型:
#include <stdio.h> int rename(const char *oldpath, const char *newpath); - 功能:类似
mv命令,可重命名文件或移动路径(如将a.txt移动到/home/user/b.txt); - 示例:
1
2rename("a.txt", "b.txt"); // 重命名a.txt为b.txt
rename("b.txt", "/home/user/docs/b.txt"); // 移动到docs目录
目录操作:mkdir() / rmdir() / opendir() / readdir()
用于目录的创建、删除与遍历,依赖<sys/stat.h>和<dirent.h>。
mkdir():创建目录
- 原型:
int mkdir(const char *pathname, mode_t mode); mode为目录权限(如0755,默认会受umask影响);- 示例:
mkdir("new_dir", 0755); // 创建new_dir目录
rmdir():删除空目录
- 原型:
int rmdir(const char *pathname); - 仅能删除空目录(非空目录需先删除内部文件/子目录);
- 示例:
rmdir("empty_dir"); // 删除空目录empty_dir
opendir() / readdir() / closedir():遍历目录
opendir(path):打开目录,返回DIR*类型的目录流;readdir(dir):读取目录项,返回struct dirent*(含文件名d_name),读取到末尾返回NULL;closedir(dir):关闭目录流;- 示例:遍历
/home/user目录下的文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int main() {
DIR *dir = opendir("/home/user");
if (dir == NULL) { perror("opendir failed"); return 1; }
struct dirent *entry;
// 循环读取目录项
while ((entry = readdir(dir)) != NULL) {
// 跳过.(当前目录)和..(父目录)
if (entry->d_name[0] == '.') continue;
printf("文件名:%s\n", entry->d_name);
}
closedir(dir);
return 0;
}
实现文件复制(类似cp命令)
通过open()/read()/write()组合,实现从源文件复制到目标文件的功能,核心是“循环读取源文件数据,写入目标文件”。
1 |
|
1 | gcc -o mycp mycp.c |
系统调用与库函数的区别
系统调用(如open()/read())与库函数(如fopen()/fread())是用户操作文件的两种接口,核心差异在于“是否依赖内核态切换”。
核心区别
| 对比维度 | 系统调用 | 库函数 |
|---|---|---|
| 定义与实现 | 操作系统内核提供的底层接口,由内核实现 | 编程语言/库(如C标准库)提供的封装函数,由用户态代码实现 |
| 运行权限 | 运行在内核态(Kernel Mode),可直接操作硬件/内核资源 | 运行在用户态(User Mode),仅能操作用户态内存,依赖系统调用实现内核级功能 |
| 功能范围 | 仅提供内核核心能力(文件I/O、进程管理等) | 覆盖通用功能:纯用户态逻辑(如strlen())、封装系统调用(如fopen()封装open()) |
| 调用成本 | 高(需切换内核态/用户态,保存/恢复上下文) | 低(纯用户态执行,仅封装系统调用时才触发内核切换) |
| 接口易用性 | 接口较底层,需手动处理FD、错误码(如errno) |
接口更友好,提供缓冲(如FILE结构体的缓冲区)、自动管理FD、简化错误处理 |
用户态到内核态的切换
现代操作系统通过“特权级隔离”保证安全(如x86的Ring 0~3),用户态程序无法直接操作硬件,需通过系统调用“委托”内核完成,流程如下:
系统调用的执行流程
- 准备参数与系统调用号:
用户程序将“系统调用号”(如open()对应编号2)存入约定寄存器(如x86的eax),并将参数存入其他寄存器(如ebx/ecx); - 触发特权级切换:
通过特殊指令(如x86的syscall、早期的int 0x80)触发中断,CPU从用户态(Ring 3)切换到内核态(Ring 0),保存用户态上下文(寄存器、栈指针); - 内核处理请求:
内核根据系统调用号查找“系统调用表”(函数指针数组),执行对应的内核函数(如sys_open()),完成硬件操作(如控制磁盘读取文件); - 返回用户态:
内核将结果存入寄存器,恢复用户态上下文,CPU切回用户态,用户程序从系统调用指令后继续执行,读取结果。
库函数的底层逻辑
库函数分两类实现:
- 纯用户态实现:不依赖系统调用,如
strlen()(遍历字符串计数)、memcpy()(内存拷贝),仅在用户态内存中执行; - 封装系统调用:如C标准库的
fopen(),内部调用open()系统调用,同时增加“用户态缓冲区”(减少内核调用次数)、FILE结构体(管理FD、缓冲区状态),示例逻辑:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// fopen()的简化逻辑
FILE* fopen(const char *path, const char *mode) {
int fd = 0;
// 1. 将库函数的mode(如"r")转换为系统调用的flags(如O_RDONLY)
if (strcmp(mode, "r") == 0) fd = open(path, O_RDONLY);
else if (strcmp(mode, "w") == 0) fd = open(path, O_WRONLY | O_CREAT | O_TRUNC, 0644);
// ... 其他mode转换
// 2. 分配FILE结构体,存储FD、缓冲区、读写状态
FILE *fp = malloc(sizeof(FILE));
fp->fd = fd;
fp->buf = malloc(4096); // 4KB用户态缓冲区
fp->buf_pos = 0; // 缓冲区当前位置
return fp;
}
文件偏移量
文件偏移量(File Offset)是内核为每个打开的FD维护的“当前读写位置计数器”,决定了read()/write()的起始位置,是实现“随机读写”的核心。
核心特性
- 与FD绑定:每个FD对应独立的偏移量,即使多个FD指向同一文件(如
open()同一文件两次),偏移量互不影响; - 初始值:
- 打开文件时默认从0开始(文件开头);
- 若以
O_APPEND模式打开,偏移量自动设为文件末尾;
- 自动更新:
调用read(fd, buf, n)或write(fd, buf, n)后,偏移量增加“实际读写的字节数”(非请求的n,因可能到文件末尾或I/O中断)。
判断文件末尾(EOF)
判断是否读到文件末尾的唯一可靠方法是检查read()的返回值是否为0:
read()返回0:已到文件末尾(无更多数据可读);read()返回-1:读取失败(需结合errno判断,如EINTR为被信号中断,可重试);- 避免用
lseek()判断(如比较偏移量与文件大小):多进程/线程操作同一文件时,偏移量可能被其他进程修改,导致判断失效;特殊文件(如管道)不支持lseek()。
1 | int fd = open("test.txt", O_RDONLY); |
O_APPEND模式对偏移量的影响
若文件以O_APPEND模式打开,每次write()前内核会自动将偏移量移到文件末尾,忽略lseek()的手动设置,确保数据始终追加到末尾(避免多进程写入时覆盖):
1 | int fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0644); |
fork()时文件的共享机制
fork()创建子进程时,子进程会复制父进程的“文件描述符表”,但父子进程的FD会指向内核中同一个文件表项,导致文件资源的共享或独立,核心取决于“文件何时打开”。
fork()前打开文件(共享文件表项)
(1)共享本质
- 父进程在
fork()前调用open()打开文件,获得FD; fork()时,子进程复制父进程的文件描述符表(FD编号相同,如父进程FD=3,子进程FD=3);- 父子进程的FD指向同一个内核文件表项(存储文件偏移量、打开模式、引用计数等),因此共享文件偏移量。
(2)示例:父子进程共享偏移量
1 |
|
(3)关键结论
- 父子进程共享文件偏移量,一方读写会影响另一方的偏移量;
- 子进程
close(fd)仅删除自己的FD表项,内核文件表项的“引用计数”减1,需父子进程均关闭FD,内核才释放文件资源。
fork()后打开文件(独立文件表项)
(1)独立本质
- 父进程先
fork()创建子进程; - 子进程在
fork()后单独调用open()打开文件,获得的FD指向新的内核文件表项(与父进程无关); - 父子进程的FD、文件表项、偏移量均独立,操作互不影响。
(2)示例:父子进程独立操作
1 |
|
(3)关键结论
- 父子进程的文件操作完全独立,一方覆盖写入不会影响另一方;
- 各自关闭自己的FD,释放对应的文件表项资源。
注意事项
- exec系列函数的影响:子进程
fork()后调用exec加载新程序,已打开的FD会被保留(除非设置FD_CLOEXEC标志),因exec仅替换代码/数据,不改变FD表; - 避免共享冲突:父子进程共享文件时,需通过同步机制(如
flock()文件锁、信号量)协调读写,防止数据覆盖;若需独立操作,应在fork()后单独open()文件。
进程替换
进程替换(Process Replacement)是Linux中通过exec系列系统调用实现的核心功能——在不创建新进程的前提下,完全替换当前进程的代码、数据与堆栈,仅保留PID等内核级元数据。这种机制是终端执行命令、程序加载的底层基础(如bash执行ls时,本质就是子进程的替换)。
进程替换的本质
当进程调用exec系列函数时,内核会执行一系列操作,实现“进程实体替换但标识不变”:
- 丢弃原有用户态资源:释放当前进程的代码段(.text)、数据段(.data/.bss)、堆和栈,仅保留内核维护的元数据(PID、PPID、进程组ID、文件描述符表、信号掩码等);
- 加载新程序:从磁盘读取目标可执行文件(如ELF格式的
ls),解析其结构,将新程序的代码段、数据段加载到内存,初始化新的堆和栈; - 更新执行上下文:将程序计数器(PC)指向新程序的入口点(通常是
_start函数,最终调用main),新程序开始执行。
核心特点:替换前后PID不变,系统仍识别为同一个进程,但执行的二进制代码、数据和逻辑被完全替换。
exec系列函数:分类与用法
Linux提供6个exec系列函数(声明于<unistd.h>),均基于底层系统调用execve封装,仅参数传递方式、路径查找逻辑、环境变量控制不同。
函数分类与核心差异
| 函数原型 | 功能说明 | 关键差异(参数/查找/环境) |
|---|---|---|
int execl(const char *path, const char *arg, ...); |
加载path路径的程序,参数以可变列表传递,需以(char*)NULL结尾 |
列表参数(l=list),需显式指定绝对/相对路径 |
int execlp(const char *file, const char *arg, ...); |
与execl类似,但file可仅为文件名,自动从PATH环境变量查找 |
列表参数+PATH查找(p=path),无需完整路径 |
int execle(const char *path, const char *arg, ..., char *const envp[]); |
与execl类似,额外通过envp自定义环境变量(不继承当前进程环境) |
列表参数+自定义环境(e=environment) |
int execv(const char *path, char *const argv[]); |
加载path路径的程序,参数以字符串数组传递,数组需以NULL结尾 |
数组参数(v=vector),需显式指定路径 |
int execvp(const char *file, char *const argv[]); |
与execv类似,file可仅为文件名,依赖PATH查找 |
数组参数+PATH查找,无需完整路径 |
int execve(const char *path, char *const argv[], char *const envp[]); |
底层系统调用原型,直接指定路径、参数数组、环境变量数组,其他exec函数均基于此实现 |
最底层,支持完整控制(路径+数组参数+自定义环境) |
关键参数解析
path/file:目标程序的路径。path需是绝对路径(如/bin/ls)或相对路径(如./a.out);file可仅为文件名(如ls),此时函数会遍历PATH环境变量中的目录(如/bin、/usr/bin)查找程序。arg/argv:命令行参数。argv是字符串数组(如{"ls", "-l", NULL}),argv[0]通常为程序名(与file一致),数组必须以NULL结尾;可变参数列表需手动以(char*)NULL结尾,避免参数解析混乱。envp:环境变量数组(如{"PATH=/bin", "USER=test", NULL})。若为NULL,新程序继承当前进程的环境变量(通过全局变量environ访问);若传入自定义数组,新程序仅使用该数组中的环境变量。
返回值规则
- 成功:函数不会返回——因为进程已被完全替换,原程序中
exec之后的代码(如错误提示)不再执行; - 失败:返回
-1,并设置errno(可通过perror()打印错误原因,如“路径不存在”“权限不足”)。
不同场景下的进程替换
单独使用exec:替换当前进程
直接调用exec会替换当前进程,适合“执行完新程序后无需返回原程序”的场景(如脚本中执行目标程序)。
1 |
|
- 执行结果:先打印“替换前:PID=xxx”,随后执行
ls -l(原程序被替换);若exec失败(如删除/bin/ls),才打印错误原因。
fork()+exec:创建子进程后替换(最常用场景)
单独使用exec会销毁原进程,因此实际开发中常先fork()创建子进程,在子进程中执行exec,父进程继续运行或等待子进程结束——这是bash执行命令、启动新程序的标准模式。
1 |
|
- 执行结果:子进程打印信息后执行
ps aux,父进程等待子进程结束后,继续打印提示(父子进程独立,子进程替换不影响父进程)。
自定义环境变量:execle/execve的用法
通过execle或execve可自定义新程序的环境变量,不依赖当前进程的环境,适合需要隔离环境的场景(如测试不同配置)。
1 |
|
- 执行结果:输出
custom_test(使用自定义的USER环境变量,而非系统默认的用户名)。
底层调用execve:完整控制路径、参数与环境
execve是所有exec函数的底层原型,需显式指定完整路径、参数数组和环境变量数组,适合需要精细控制的场景。
1 |
|
- 执行结果:替换为
ps -f,新程序可通过printenv MY_KEY(若在新程序中打印环境变量)看到MY_KEY=hello。
进程替换的关键特性
PID与核心标识不变
替换前后,进程的PID、PPID、进程组ID、会话ID等内核级标识完全不变——系统仍认为是“同一个进程”,仅执行的代码和数据被替换。例如:
- 替换前PID=1234,替换后执行
ps -p 1234,仍能看到该进程,但CMD列变为目标程序(如ls)。
文件描述符默认保留
原进程打开的文件描述符(FD)会被新程序继承(除非设置了FD_CLOEXEC标志)——新程序可通过继承的FD操作原文件,无需重新打开。
示例:父进程打开文件,子进程继承FD并写入:
1 |
|
- 执行结果:
test.txt中会写入“继承FD写入的内容”——新程序通过/proc/self/fd/3(指向继承的FD=3)操作原文件。
信号处理方式重置
替换前原进程注册的自定义信号处理函数(如signal(SIGINT, handler))会被重置为默认行为(除SIG_IGN忽略的信号)——因为新程序的代码段已替换,原处理函数的地址失效,无法继续调用。
例如:原进程将SIGINT(Ctrl+C)的处理函数设为自定义handler,替换后新程序收到SIGINT会默认终止(而非执行原handler)。
环境变量可自定义
通过execle或execve的envp参数,可完全自定义新程序的环境变量,不继承当前进程的环境——适合需要环境隔离的场景(如测试不同配置、安全沙箱)。
fork()与exec的配合:启动新程序的标准模式
fork()+exec是Linux中“启动新程序”的标准模式,解决了“单独使用exec会销毁原进程”的问题,核心逻辑如下:
- fork()创建子进程:复制父进程的代码、数据和FD,子进程与父进程完全相同;
- 子进程exec替换:子进程调用
exec替换为目标程序,父进程不受影响; - 父进程wait回收:父进程通过
wait()或waitpid()等待子进程结束,回收其资源,避免僵尸进程。
这种模式是bash、进程管理器(如systemd)、终端命令执行的底层实现——例如在bash中输入ls时:
bash调用fork()创建子进程;- 子进程调用
execvp("ls", {"ls", NULL})替换为ls程序; bash(父进程)调用wait()等待ls执行完毕,随后回到命令提示符,等待用户输入下一条命令。
bash的底层逻辑:exec与fork的协同
bash作为命令解释器,执行外部命令(如ls、ps)时,核心依赖“fork子进程+exec替换”,而执行内置命令(如cd、pwd)时无需fork——这是理解bash工作原理的关键。
为什么bash要“fork子进程”?
若bash直接调用exec替换自身为目标命令,会导致两个严重问题:
bash进程被销毁:执行完ls后,用户失去交互界面,需重新启动bash;- 无法连续执行多命令:如
ls && cd ..,第一个命令执行后bash已被替换,第二个命令无法执行。
因此,bash必须通过fork创建子进程,让子进程执行exec替换——父进程bash始终存活,持续接收后续命令。
bash执行外部命令的完整流程
以用户输入ls -l为例,bash的执行步骤如下:
- 解析命令:
bash识别ls是外部命令(非内置),拆分参数为ls和-l; - fork子进程:
bash调用fork(),创建与自身完全相同的子进程(子进程PID新,PPID为bash的PID); - 子进程exec替换:子进程通过
execvp("ls", {"ls", "-l", NULL}),从PATH找到/bin/ls,替换为ls -l程序,开始执行列表功能; - 父进程wait回收:
bash调用wait(),阻塞等待子进程ls执行完毕,回收其退出状态(如退出码0表示成功); - 回到交互状态:
bash打印命令提示符(如user@host:~$),等待用户输入下一条命令。
内置命令vs外部命令:是否需要fork?
bash中的命令分为两类,执行逻辑差异显著:
- 内置命令(如
cd、pwd、export):命令逻辑由bash自身代码实现,无需fork子进程,直接在bash进程内执行。例如cd /home——bash直接修改自身的当前工作目录,执行效率高,且能修改bash的环境(如export设置环境变量); - 外部命令(如
ls、ps、gcc):命令逻辑在独立的可执行文件中,必须通过“fork子进程+exec替换”执行,避免影响bash本身。
示例:
- 输入
cd /tmp:bash直接执行内置cd逻辑,不创建子进程; - 输入
ls /tmp:bash先fork子进程,再在子进程中exec替换为ls。
进程替换的核心是“PID不变,代码数据替换”,通过exec系列函数实现;fork()+exec是启动新程序的标准模式,也是bash执行外部命令的底层逻辑。理解这一机制,能深入掌握Linux进程管理的核心,解决多程序协作、命令执行等实际问题。