Linux系统上C程序的编译与调试
gcc 分步编译链接
GCC(GNU Compiler Collection)是一套功能强大的编译器套件,可将 C/C++ 等源代码转化为可执行程序。从源代码(.c)到可执行程序的过程分为预编译、编译、汇编、链接四个核心阶段,每个阶段生成特定格式的中间文件,最终输出可执行程序。这些过程共同搭建了从 “人类可读的高级语言” 到 “机器可执行的二进制指令” 的桥梁,最终产物需加载到计算机存储器(内存)中,由控制器按指令顺序调度,运算器执行算术 / 逻辑运算,通过输入设备(如键盘)获取数据,输出设备(如显示器)展示结果,完成程序功能。
预编译(Preprocessing)
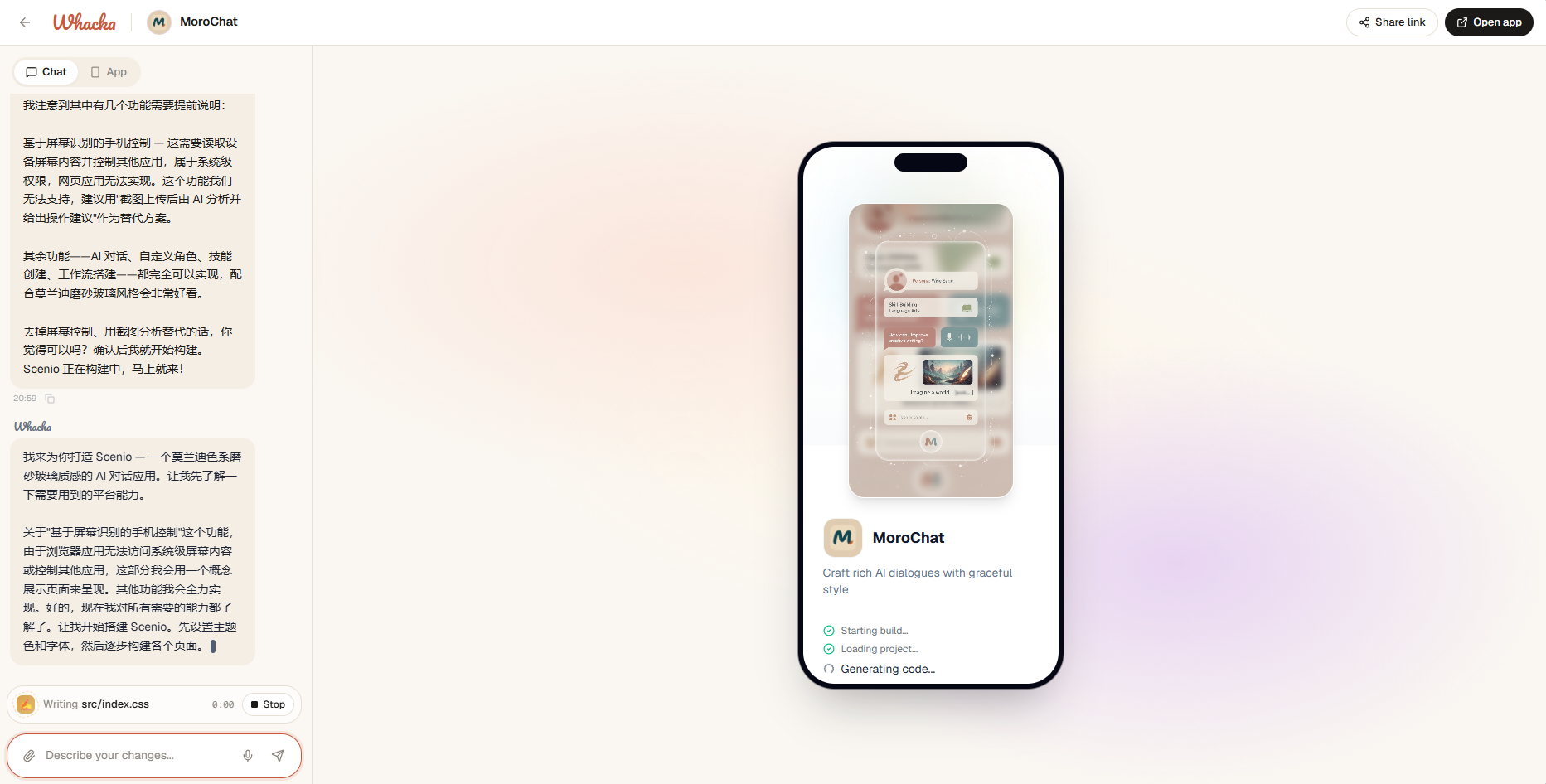
命令:gcc -E main.c -o main.i作用是处理源代码中的预处理指令,生成预处理后的文本文件(.i)。具体操作包括展开所有#include头文件(将头文件内容插入当前文件)、处理所有#define宏定义(替换宏名与宏体,删除#define指令)、删除注释(//或/*...*/)、处理条件编译指令(如#if、#elif、#else、#endif,保留满足条件的代码)。输出文件为main.i(纯文本,保留 C 语法结构,但已展开预处理内容)。
1 | //main.c |
1 | //main.i |
编译(Compilation)
命令:gcc -S main.i -o main.s作用是将预处理后的.i文件转化为汇编代码(.s)。具体操作包括对代码进行语法分析(检查语法错误)、语义分析(检查逻辑合理性,如变量未定义)、进行代码优化(如常量折叠、死代码删除,可通过-O[0-3]选项控制优化级别,-O0无优化,-O3为最高优化,优化后程序运行更快但编译时间更长)、将高级 C 语法转化为对应架构的汇编指令(如 x86、ARM 汇编)。输出文件为main.s(汇编语言文本,包含 CPU 可理解的低级指令)。

汇编(Assembly)
命令:gcc -c main.s -o main.o(也可直接对.c文件执行:gcc -c main.c -o main.o 或 gcc -c main.c,跳过手动预编译和编译步骤)作用是将汇编代码(.s)转化为机器码(二进制指令),生成目标文件(.o)。具体操作是汇编器(as)将每条汇编指令翻译为对应 CPU 的二进制机器码,生成目标文件(.o,Linux 下为 ELF 格式,Windows 下为 COFF 格式),包含二进制指令、数据、符号表(变量 / 函数名与地址的映射)等信息。目标文件是单个源代码编译后的二进制文件,不可独立执行;与之相关的还有静态库(.a,Linux)/(.lib,Windows)—— 多个目标文件的归档文件,链接时会被完整复制到可执行程序中,优点是可执行程序独立运行,缺点是体积大、更新需重新编译;以及动态库(.so,Linux)/(.dll,Windows)—— 链接时仅记录库文件的引用,运行时由操作系统动态加载,优点是体积小、更新方便,缺点是依赖库文件存在。

链接(Linking)
命令:gcc main.o -o main(Linux 生成main,Windows 生成main.exe)作用是将多个目标文件(.o)及所需库文件(静态库或动态库)合并,生成可执行程序。具体操作包括符号解析(将不同目标文件中的符号如函数调用、变量引用与实际地址关联,例如main.o中调用的add()函数在add.o中定义,链接器需找到其地址)、重定位(调整目标文件中指令的地址,目标文件中地址为相对地址,链接后需转为绝对地址,确保 CPU 能正确寻址)、合并代码段与数据段(将多个目标文件的代码和数据合并为统一的段)。链接时可通过-L<dir>指定库文件搜索路径,-l<lib>指定需链接的库(如-lm表示链接数学库libm.so)。输出文件为可执行程序(Linux 为 ELF 格式,Windows 为 PE 格式,可直接被操作系统加载执行)。

多文件编译
当程序包含多个源代码文件(如main.c、add.c、max.c)时,可通过以下方式编译:
分步编译 + 链接(推荐,适合大型项目):
1 | gcc -c main.c -o main.o # 编译main.c为main.o,可添加-Wall显示所有警告信息(如未使用变量、类型不匹配)辅助排查问题 |
一步编译(适合小型项目,GCC 自动完成预编译→编译→汇编→链接):

1 | gcc -o main main.c add.c max.c # 直接生成可执行程序main |
不同平台存在一定差异:可执行文件格式上,Linux 为 ELF(Executable and Linkable Format),Windows 为 PE(Portable Executable);删除目标文件时,Linux 使用rm *.o,Windows(CMD)使用del *.o,PowerShell 使用Remove-Item *.o。
编译链接过程
预编译阶段
预编译是对源代码的文本级预处理,核心是完成文本替换与指令解析,最终生成 .i 后缀的预处理文件。
此阶段会删除所有 #define 指令,并递归展开代码中的宏定义——例如 #define MAX 100 定义后,代码中 int a = MAX; 会被替换为 int a = 100;,确保后续阶段无需再处理宏。
同时,预编译会处理 #if #ifdef #elif #else #endif 等条件指令,根据条件保留或剔除代码块。若未定义 DEBUG 宏,#ifdef DEBUG 与 #endif 之间的调试代码(如 printf("调试信息"))会被直接删除,仅保留有效逻辑。
对于 #include 指令,预编译会将头文件完整插入指令位置,若头文件嵌套包含(如 stdio.h 包含 stddef.h),则递归完成插入。头文件引用路径遵循规则:<stdio.h> 从系统默认路径(如 Linux 的 /usr/include)查找;"myheader.h" 先查当前目录,再查系统路径。
此外,所有注释(// 单行注释 或 /* 多行注释 */)会被删除
例如 int add(int x, int y); // 加法函数
处理后变为 int add(int x, int y);。
同时,文件中会隐式添加行号与文件名标识(如 # 1 "main.c"),为后续报错提供定位依据。#pragma 等编译器专属指令(如 #pragma pack(4) 设定内存对齐)会被完整保留,传递给编译阶段。
编译阶段
编译阶段将 .i 预处理文件转化为 .s 后缀的汇编文件,核心是完成语法分析、优化与符号汇总。
首先进行词法分析,将代码拆分为最小语法单元(Token):关键字(int return)、标识符(add x)、运算符(+ =)、标点(; {)等,每个 Token 会被标记类型,为后续分析奠基。
随后进入语法分析,编译器依据 C 语法规则将 Token 组合为抽象语法树(AST)。例如 return x + y; 会被解析为“返回操作包含加法操作,加法操作的操作数为 x 和 y”。若存在语法错误(如缺少分号、括号不匹配),编译器会在此阶段报错。
语法通过后进行语义分析,检查逻辑合法性:验证变量是否声明后使用、函数参数类型是否匹配、返回值是否与声明一致等。例如 int add(int x, int y) 若被调用为 add(3.5, 4),会因参数类型不匹配报错。同时会进行类型推导与转换,确保符合 C 语言类型规则。
接下来是代码优化,分为局部与全局优化:局部优化针对代码块(如 int a = 3 + 5; 优化为 int a = 8;),全局优化针对函数间逻辑(如调整循环结构减少执行次数)。优化后代码逻辑不变,但效率更高、占用空间更小。
最后汇总符号信息,形成初步符号表,记录变量名、函数名的类型、位置等——例如 add 函数会被标记为返回 int、含 2 个 int 参数,为汇编与链接阶段提供依据。
汇编阶段
汇编阶段将 .s 汇编文件转化为 .o 后缀的二进制目标文件(Linux 系统),核心是完成汇编指令到机器码的转换。
此阶段会逐行解析汇编指令(如 mov add ret),将其转换为 CPU 可识别的二进制机器码——例如 add eax, ebx 会被转为对应的二进制指令,确保 CPU 可执行。
同时,目标文件会被划分为多个 section(段):.text 段存储二进制代码(函数执行指令)、.data 段存储已初始化的全局/静态变量(如 int g_val = 10;)、.bss 段记录未初始化的全局/静态变量(仅记大小和数量,不占磁盘空间,运行时由系统分配内存)。
此外,汇编阶段会完善符号表,补充符号所在的 section 及偏移量。例如 add 函数会被标记位于 .text 段、偏移量 0x08;全局变量 g_val 位于 .data 段、偏移量 0x04。此时外部符号(如 printf)地址未确定,会被标记为“未解析”,等待链接处理。
生成的 .o 文件为二进制文件,因含未解析符号且缺少运行初始化代码(如设置栈指针),无法直接执行,需经链接阶段处理。
链接阶段
链接阶段将多个 .o 目标文件与系统库文件合并为可执行文件(Linux 无后缀,Windows 为 .exe),核心是完成段合并、符号解析与重定位。
首先,链接器会合并所有目标文件的相同 section:将多个 .text 段合并为一个,.data 段同理,并为合并后的 section 分配虚拟地址。操作系统会为可执行文件分配虚拟地址空间,链接器依据规则为每个 section 设定唯一起始地址,确保代码与数据在内存中有明确位置。
接着合并符号表,形成全局符号表并进行符号解析:解决“未解析符号”的引用问题。例如代码中调用的 printf 函数,会在系统库(如 libc.so)中查找定义,找到后填入地址;若未找到,会报“未定义引用”错误。
最后进行符号重定位:将汇编阶段使用的 section 内偏移量修正为最终虚拟地址。例如 add 函数在汇编阶段的偏移量为 .text 段内 0x08,合并后 .text 段起始地址为 0x400500,则所有引用 add 的地址会被修正为 0x400508,确保程序运行时能正确寻址。
链接分为静态与动态两种:静态链接将库代码完整复制到可执行文件,体积大但可独立运行;动态链接仅记录库引用,运行时加载动态库(如 libc.so),体积小但依赖库存在。
makefile和make
Makefile与make的关系
make 是Linux下的工程编译工具,负责按规则执行编译操作;Makefile 是规则配置文件,记录“如何编译文件、依赖关系、执行顺序”等信息。二者配合可实现多文件工程的自动化编译——无需每次手动输入冗长的gcc命令(如gcc main.c add.c max.c -o main),仅需执行make,工具就会按Makefile规则自动完成编译,尤其适合文件多、依赖复杂的工程。
Makefile基础语法规则
Makefile的核心是“目标(Target)- 依赖(Prerequisites)- 命令(Commands)”的三段式结构,语法严格,命令行必须以Tab键开头(空格缩进会报错,是常见陷阱)。
基本结构为:
1 | 目标: 依赖文件1 依赖文件2 ... |
- 目标:要生成的文件(如可执行文件
main、中间文件add.o)或操作(如clean清理)。 - 依赖:生成“目标”所需的文件(如生成
main需要main.o/add.o/max.o,生成add.o需要add.c)。 - 命令:通过依赖生成目标的具体操作(如
gcc -c add.c -o add.o),必须以Tab开头。
编译main.c/add.c/max.c
工程包含3个C文件(main.c调用add和max函数)、2个头文件(add.h和max.h声明函数)
工程文件列表
1 | 工程目录/ |
完整Makefile内容
1 | # 定义变量(方便统一修改) |
编译与清理操作
执行编译:在工程目录输入
make,工具按以下顺序执行:检查all目标依赖main,转去处理main;检查main依赖的.o文件,若不存在或对应.c/.h有修改,先编译生成.o;最后链接所有.o,生成main。
执行清理:输入
make clean,执行rm -rf命令,删除所有中间.o文件和main,恢复工程初始状态。
调试配置与灵活修改
调试配置(添加GDB调试信息)
可通过变量控制是否生成调试信息,修改CFLAGS即可:
1 | # 方式1:固定开启调试(支持gdb) |
开启后,可通过gdb ./main进入调试模式,设置断点、单步执行等。
灵活修改:用变量简化维护
工程变大时,修改编译器(如gcc换clang)或编译选项(如加-O2优化),直接改开头变量即可,无需逐个改命令:
1 | CC = clang # 更换编译器 |
与VS的对比差异
| 对比维度 | Makefile + make | Visual Studio(VS) |
|---|---|---|
| 操作环境 | 基于Linux命令行,纯文本配置 | 图形化IDE,可视化操作 |
| 规则管理 | 需手动编写Makefile,定义依赖和命令,灵活度高 | 自动生成工程文件(.sln/.vcxproj),无需手动写规则 |
| 适用场景 | 适合Linux环境、轻量工程、需自定义编译流程 | 适合Windows环境、大型可视化项目、快速搭建环境 |
| 核心优势 | 无图形界面依赖,跨平台(Linux/macOS),过程透明 | 集成调试、代码补全、UI设计等一站式功能,门槛低 |
实用技巧补充
- 伪目标声明(.PHONY):若工程有
clean文件,make clean会误判“目标已存在”。添加.PHONY: all clean声明伪目标,确保命令始终执行。 - 隐含规则简化:make自带隐含规则(如自动将
add.c编译为add.o),可省略add.o: add.c add.h这类规则,简化代码。 - 多目标编译:需生成多个可执行文件(如
main和test),可添加多个目标:1
2
3
4
5
6TARGETS = main test # 多个目标
all: $(TARGETS)
main: main.o add.o max.o
$(CC) $(CFLAGS) $^ -o $@ # $^代表所有依赖,$@代表当前目标
test: test.o add.o
$(CC) $(CFLAGS) $^ -o $@
GDB调试
Debug 版本与 Release 版本的核心差异
在 C 语言开发中,根据用途不同,可执行文件分为 Debug(调试)和 Release(发行)两个版本,核心区别在于是否包含调试信息及优化程度。
Debug 版本:用于开发调试
Debug 版本是为开发人员设计的可调式版本,生成的可执行文件中包含完整的调试信息(如变量地址、函数调用栈等),方便通过 GDB 等工具追踪代码执行过程、定位错误。
生成方式:调试信息需在编译阶段加入,通过gcc的-g选项控制 —— 该选项会让编译器在中间文件(.o)和最终可执行文件中嵌入调试符号。常见命令:
- 分步编译:
gcc -c hello.c -g(生成含调试信息的hello.o),再gcc -o hello hello.o(链接生成可执行文件); - 一步编译:
gcc -o test test.c -g(直接生成含调试信息的test)。
特点:
- 包含调试信息,文件体积较大;
- 几乎不做代码优化(避免优化导致调试时变量值异常或代码逻辑跳转);
- 仅用于开发阶段,不适合直接提供给用户。
Release 版本:用于用户发行
Release 版本是最终提供给用户的发行版本,默认不包含调试信息,且会启用编译器优化(如代码精简、循环优化等),以提升程序运行效率、减小文件体积。
生成方式:gcc默认生成的就是 Release 版本,无需额外选项。例如:
gcc -o app main.c(直接生成无调试信息、经过优化的app)。
特点:
- 无调试信息,文件体积小、运行效率高;
- 启用编译器优化(默认
-O0无优化,可通过-O1/-O2/-O3手动开启更高优化); - 不适合调试(缺少调试符号,GDB 无法追踪变量或函数调用)。
GDB 基础调试:单进程单线程
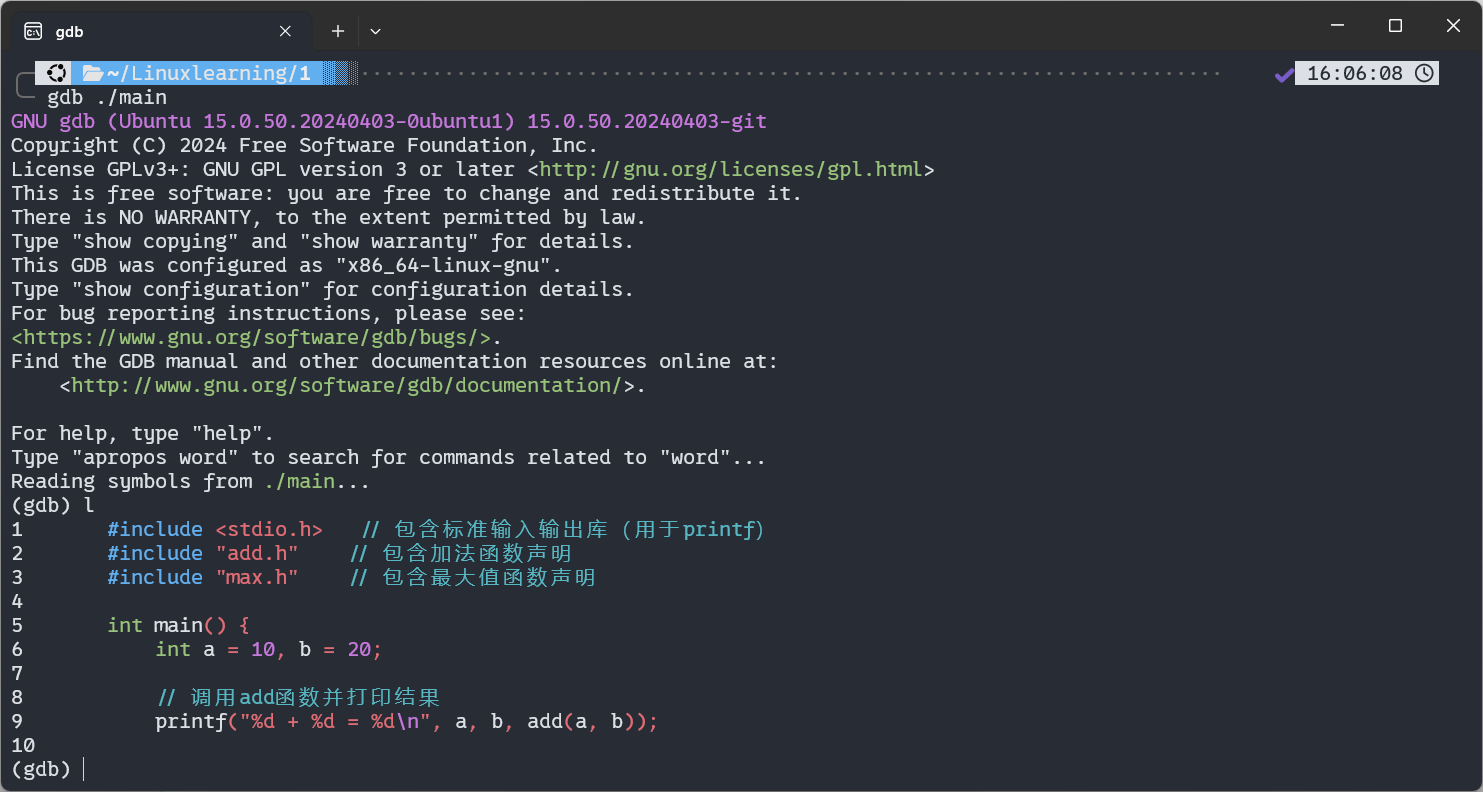
GDB(GNU Debugger)是 Linux 下常用的调试工具,通过gdb 可执行文件名进入调试模式(需使用 Debug 版本的可执行文件)。以下是高频调试命令及用法:
查看源代码
l(list):默认显示main函数所在文件的源代码,每次显示 10 行左右,多次执行可继续向下翻页;list 文件名:行号:指定显示某文件某行上下的代码,例如list add.c:5(显示add.c第 5 行附近的代码)。
断点操作
断点是调试的核心,用于暂停程序执行,方便观察变量状态或代码逻辑。
b 行号:在当前文件指定行添加断点,例如b 10(在第 10 行设断点);b 函数名:在指定函数的第一行有效代码处添加断点,例如b add(在add函数入口设断点);info break:查看所有断点信息(包括断点号、位置、状态);delete 断点号:删除指定断点,例如delete 2(删除 2 号断点);disable 断点号:临时禁用断点(不删除,后续可启用),不加编号则禁用所有;enable 断点号:启用被禁用的断点,不加编号则启用所有。
程序执行控制
r(run):启动程序,执行到第一个断点处暂停;n(next):单步执行,遇到函数调用时不进入函数内部(直接执行完函数并暂停);s(step):单步执行,遇到函数调用时进入函数内部(在函数第一行暂停);c(continue):继续执行程序,直到下一个断点处暂停;finish:从当前函数内部跳出,执行完函数后暂停(常用于退出深层调用的函数);q(quit):退出 GDB 调试模式。
变量与表达式查看
p val(print val):打印变量val的值,例如p a(显示变量a的当前值);p &val:打印变量val的地址,例如p &b(显示b的内存地址);p 表达式:计算并打印表达式结果,例如p x + y * 2(显示x + y*2的值);p 数组名:打印整个数组的元素,例如p arr(显示arr数组的所有元素);p *指针@长度:通过指针打印指定长度的数组元素,例如p *parr@5(通过parr指针打印 5 个元素);ptype val:显示变量val的类型,例如ptype str(显示str是char*还是int等)。
自动显示与函数栈
display 变量/表达式:设置自动显示,程序每次暂停时都会自动打印指定内容,例如display i(每次暂停都显示i的值);info display:查看所有自动显示的设置(包括编号);undisplay 编号:删除指定的自动显示,例如undisplay 1(删除 1 号自动显示项);bt(backtrace):显示当前函数调用栈,即 “谁调用了当前函数”“当前函数又调用了谁”,常用于定位程序崩溃时的调用路径。
GDB 进阶调试:多进程与多线程
当程序包含多个进程或线程时,需使用 GDB 的进程 / 线程控制命令,避免调试混乱。
多进程调试
多进程程序中,fork()会创建子进程,GDB 默认只跟踪父进程,需通过设置指定调试目标:
set follow-fork-mode mode:选择跟踪父进程(parent)或子进程(child),例如set follow-fork-mode child(切换为调试子进程)。
注意:未被跟踪的进程会直接执行结束,若需同时调试多个进程,需配合set detach-on-fork off(禁止 GDB 与未跟踪进程分离),再通过inferior命令切换进程。
多线程调试
多线程程序中,线程共享内存空间,调试时需明确当前操作的线程:
info threads:查看所有线程信息(包括线程 ID、状态、所在函数);thread 线程ID:切换调试目标到指定线程,例如thread 2(开始调试 2 号线程);set scheduler-locking 模式:控制线程调度(避免其他线程干扰调试):off:不锁定任何线程(默认,所有线程随调试执行);on:仅当前调试的线程运行,其他线程暂停;step:单步执行时,仅当前线程运行(适合细致调试某线程逻辑)。
通过合理区分 Debug/Release 版本,并熟练使用 GDB 命令,可高效定位代码中的逻辑错误或内存问题,尤其在多文件、多进程 / 线程的复杂工程中,调试工具能显著提升开发效率。